
Please have a seat (if you haven’t already), and let me introduce myself. I am a Bayesian psychometrician and expert in Bayesian statistical modeling, working at the intersection of psychometrics and experimental psychology. Currently, I’m doing my PhD at the Cognition, Attention and Learning Lab at Universidad Autónoma de Madrid, Spain.
My research aims to bridge psychometrics and experimental psychology by developing and validating psychometric measurement models tailored to experimental paradigms. These models allow researchers to estimate the latent common factors underlying multiple experimental tasks, leading to a more robust and generalizable understanding of cognitive processes.
My first love: Psychology
My journey in psychology began at the Complutense University of Madrid, where I first wanted to become a clinical psychologist (yes, really). That pulled me toward psychopathology and the basic cognitive processes behind it, like attention and memory. But life had other plans: I ended up doing a PhD not in therapy or diagnosis, but in how to measure basic psychological processes accurately within experimental designs.
How did that happen? Out of skepticism, and honestly, a bit of ignorance. The more I got into research, the more I realized how little I understood about the statistical machinery behind our conclusions. Reading papers without understanding the methods started to feel like an act of faith, and I wasn’t comfortable with that. So I took what seemed like a small detour that ended up redirecting my whole career: I immersed myself in methodology, statistics, and psychometrics to figure out how the models we use actually work, especially when they fail and produce artifacts that researchers might mistake for real findings. I’m a bit of a skeptic, I suppose.
My true love: Psychometrics
To me, psychometrics is the most important discipline in psychology. It safeguards the quality of our measurements by examining the sources of validity evidence and the reliability of psychological constructs. Without measurement, there is no research; and with measurement, every substantive conclusion ultimately depends on the strength of the validity evidence supporting the interpretation of those scores. How could I not fall in love with that?
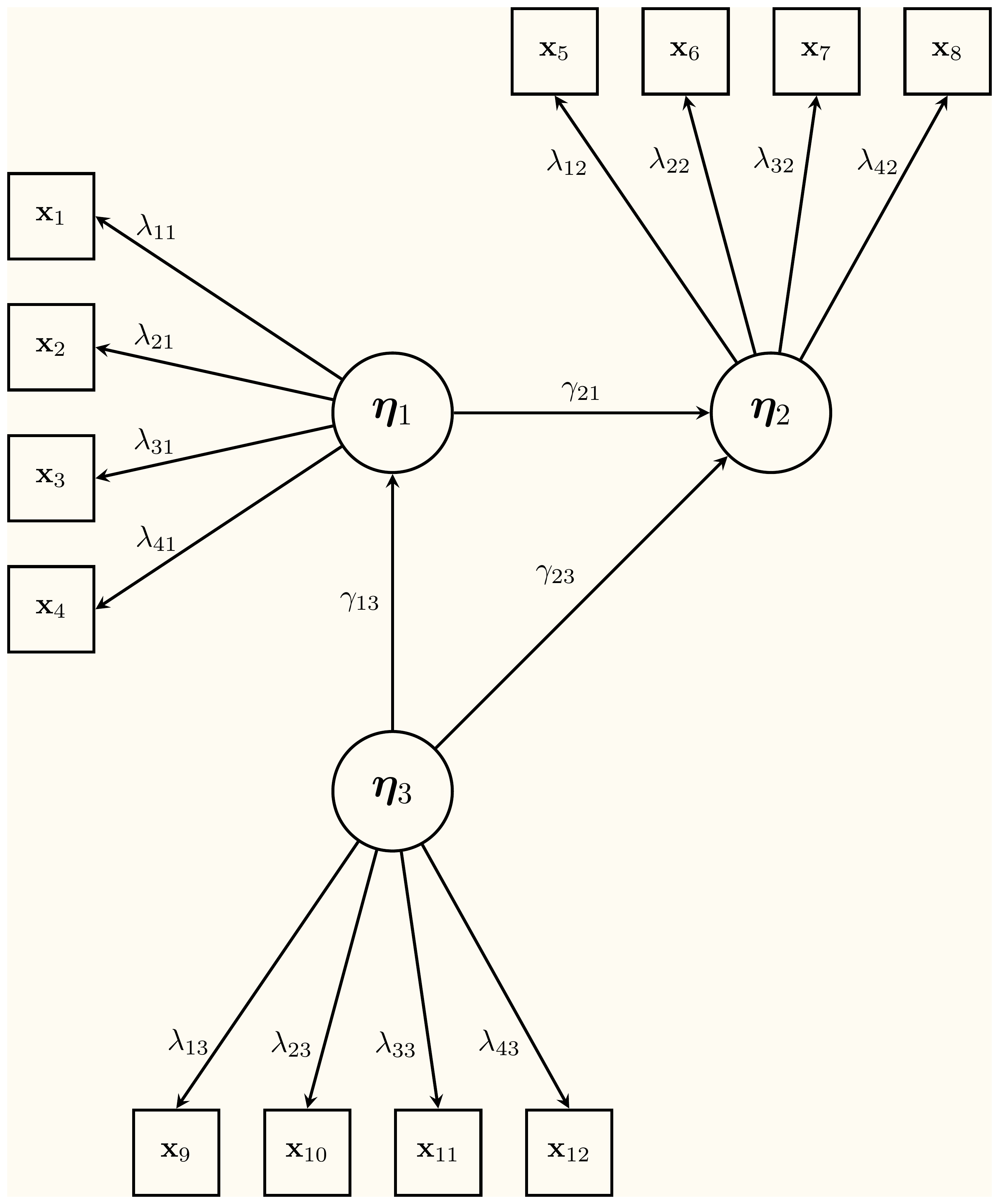
Psychometrics starts from a simple but powerful idea: what we observe are imperfect reflections of latent constructs that cannot be directly measured. Those reflections show up in questionnaire items, task performances, or behavioral measures, each capturing the construct in its own imperfect way. Psychometric models help us make sense of that imperfection by linking observed variables to latent constructs, accounting for measurement error, and letting us study structural relations among psychological constructs.
That perspective changed how I think about research. Measurement stopped being a technical step and became a way of connecting data to theory. In fact, the substantive conclusions researchers care about most are precisely the structural part of psychometric models: the relations among latent constructs that give psychological theory its meaning.
My toxic love: Bayesian Statistics
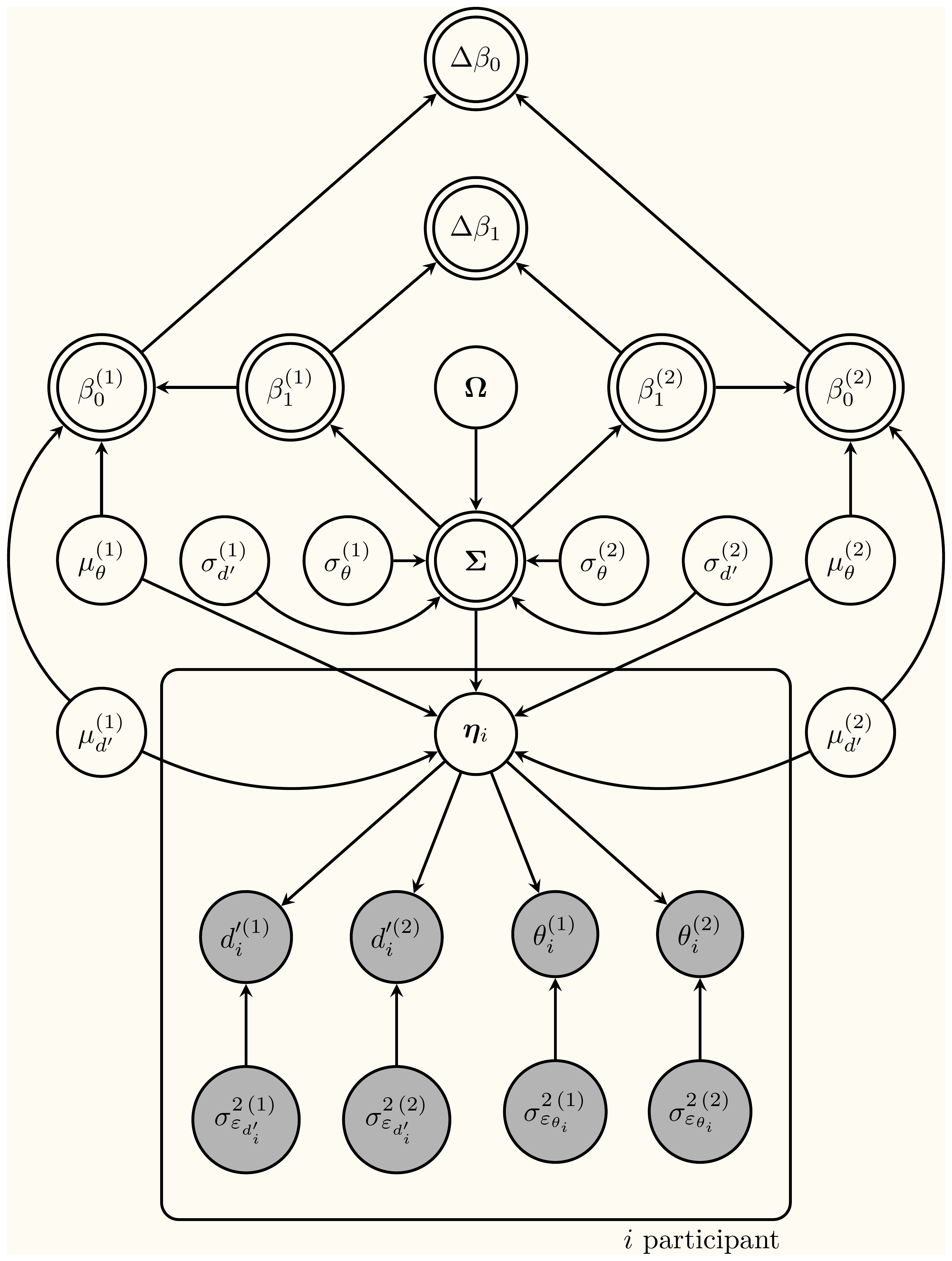
Bruno de Finetti once said that “probability does not exist.” It sounds like a philosophical stunt, but consider something close to home. A friend of mine is expecting a baby. He says the probability that the child has XY chromosomes is slightly higher than the probability that they have XX chromosomes. But the child’s chromosomes are not probabilistic. Leaving aside rare chromosomal variations, they are already XX or XY. It is already a fact. He just does not know it yet. And that is exactly what De Finetti meant. Probability is not a feature of the world; it is not in the baby. It lives in what we know and in how we think.
That idea planted a new seed of doubt about my own work, since every frequentist model deals with probability in one way or another. What started as a small detour into Bayesian statistics quickly became an obsession, and, unexpectedly, it helped me understand frequentist methods more clearly than before. All the frequentist statistics we know are simply a particular case of Bayesian statistics, much like a golden retriever is just one breed of dog. And the frequentist version is probably the most cumbersome of the bunch.
Maybe that’s why those who discover Bayesian statistics rarely go back. It’s not just a different way of analyzing data, but a more flexible way of thinking. It lets you build and test virtually any model you can imagine, quantify uncertainty in a natural and intuitive way, and work without relying on asymptotic assumptions that often make little sense in practice. In my view, the Bayesian approach, especially in applied research, is far more transparent and honest about its assumptions than any frequentist model.